Generating an image with a neural network is usually a task that needs a separate app, service, or web browser. Midjourney, DALL-E, Ideogram, and others — each has its own interface and settings. The Image Generation module in VELA's AI assistant removes the need to open a third-party app or website: describe the image in a Telegram chat — and get the result right there in a few seconds.
What the module does and which plan it's on
The module works on the Pro plan ($9/mo, paid by card or Telegram Stars). It's not available on the free Basic plan.
Under the hood — Flux Dev by fal.ai. It's a modern diffusion model with detailed quality and good style rendering.
What it can do:
Create images from a text description
Three formats: square, horizontal (landscape), vertical (portrait)
Up to 10 generations a day — the limit resets daily
The module works best with landscapes, nature, conceptual scenes, and abstract art. It does worse with logos, text in the image, and accurate fonts — that's a general limitation of diffusion models, not specific to this VELA module.
The module is active automatically on the Pro plan — no extra settings in the dashboard required.
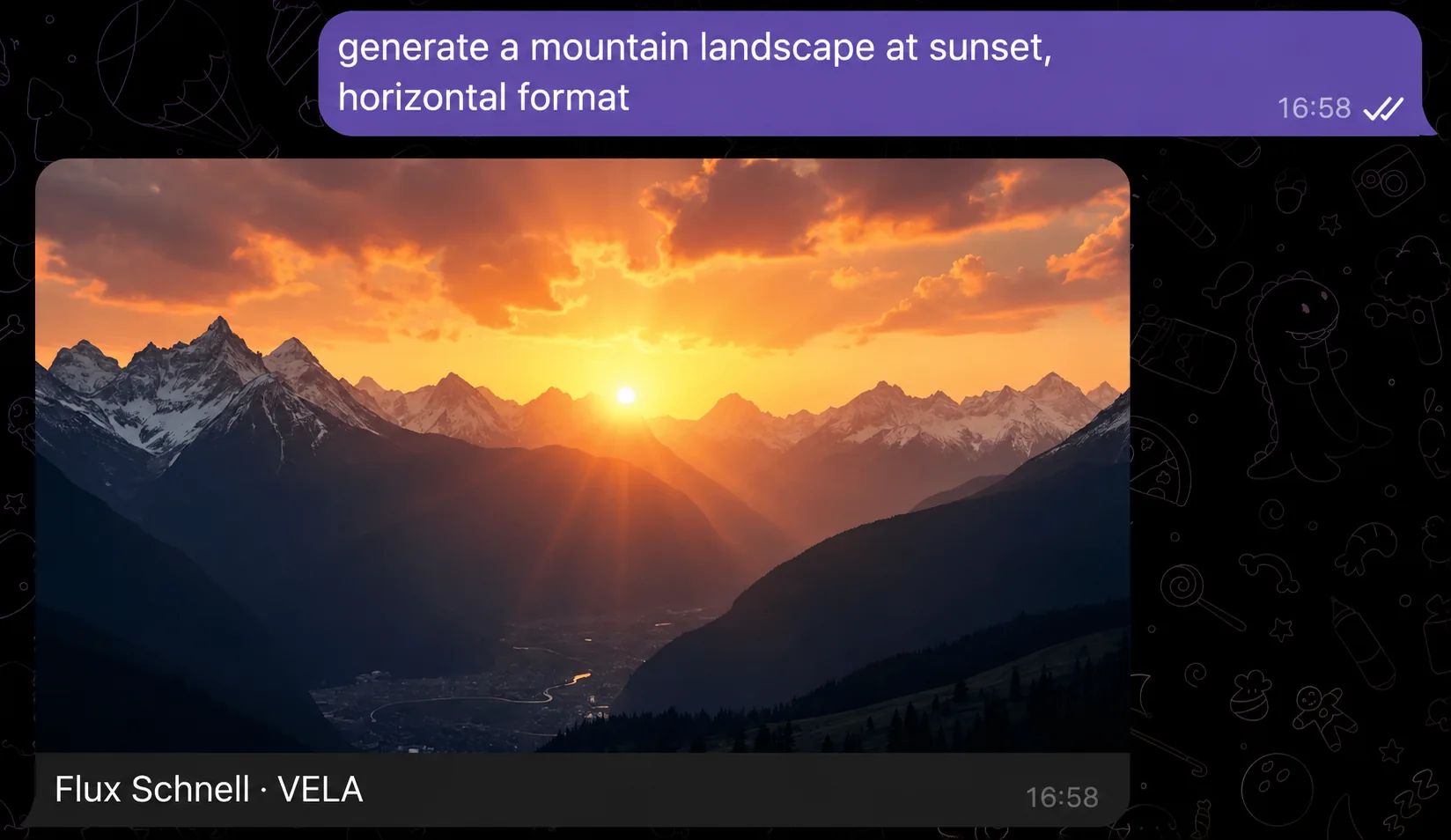
How to connect
No separate activation needed. If you're on Pro — write a generation request in the Telegram chat and the AI assistant replies with a finished image. No tokens, no keys, no settings.
The only setting you make explicitly is the format. If you don't specify it, the AI assistant picks square by default. To get a horizontal or vertical image, just add that to the request.
How to use it: example requests
The AI assistant understands natural language. Describe the scene however you like — no special commands or syntax.
Basic example requests:
"Draw a sunset over a mountain lake, warm colors"
"Generate an astronaut riding a unicorn, cyberpunk style"
"Abstract art in blue and gold tones, vertical"
"An autumn forest with fog, morning light, horizontal format"
"A minimalist cityscape at night, rain"
The more specific the description, the closer the result is to what you expect. Add style (watercolor, cyberpunk, minimalism), lighting (sunset, morning, night), mood (fog, rain, snow), and format (square, horizontal, vertical).
If the result isn't what you wanted, describe what to change: "the same, but darker tones" or "a similar scene, but without people". The AI assistant generates a new version.
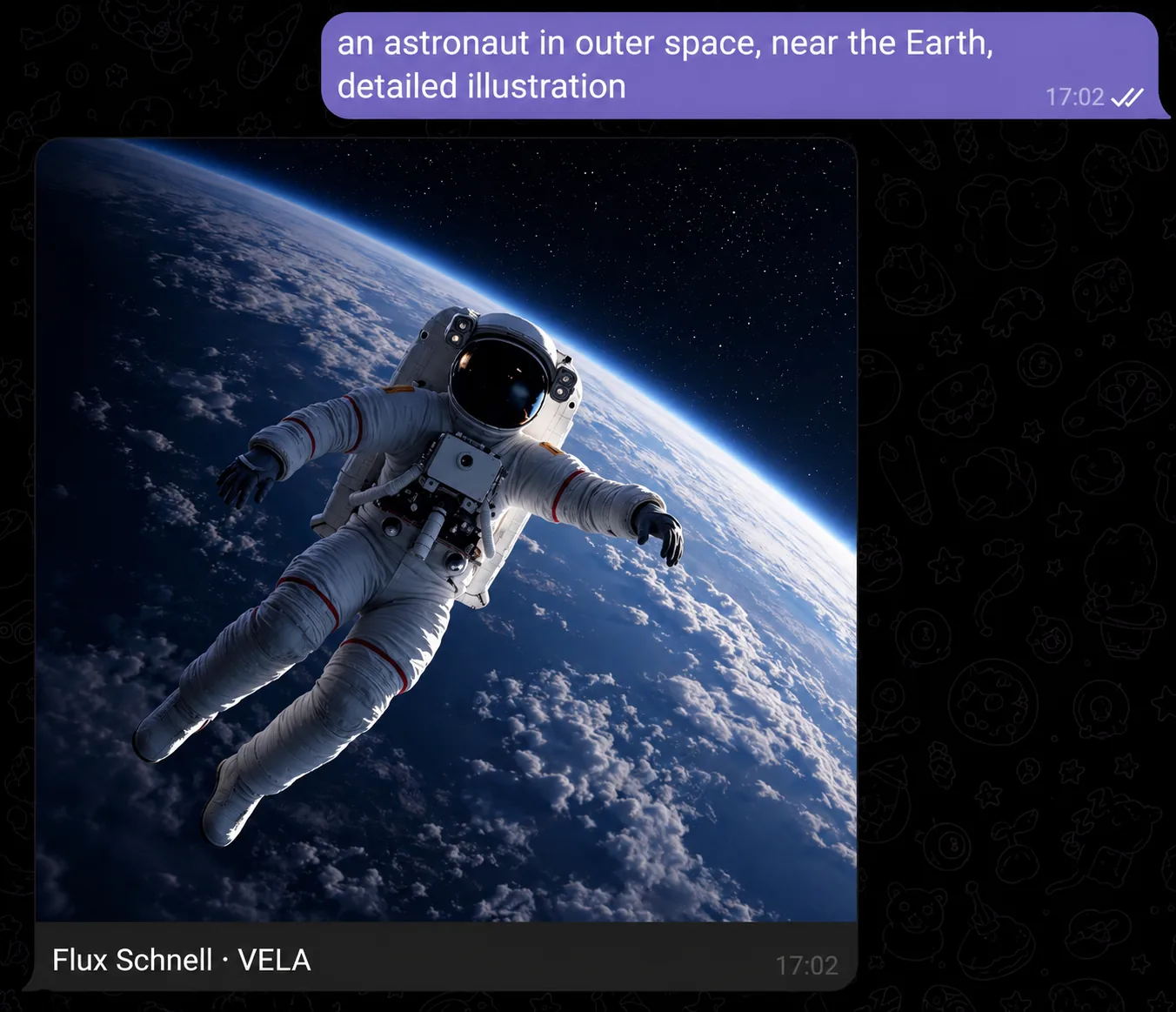
By voice
You don't have to type. The AI assistant recognizes voice messages and handles them just like text.
Dictate: "draw a mountain landscape with a river and autumn trees, horizontal" — and get the image without a single keystroke. Handy on the go, in transit, or when typing is awkward.
Long, technical descriptions with lots of detail are better typed — it's harder to phrase precisely by voice. But for most scenes, voice works great.
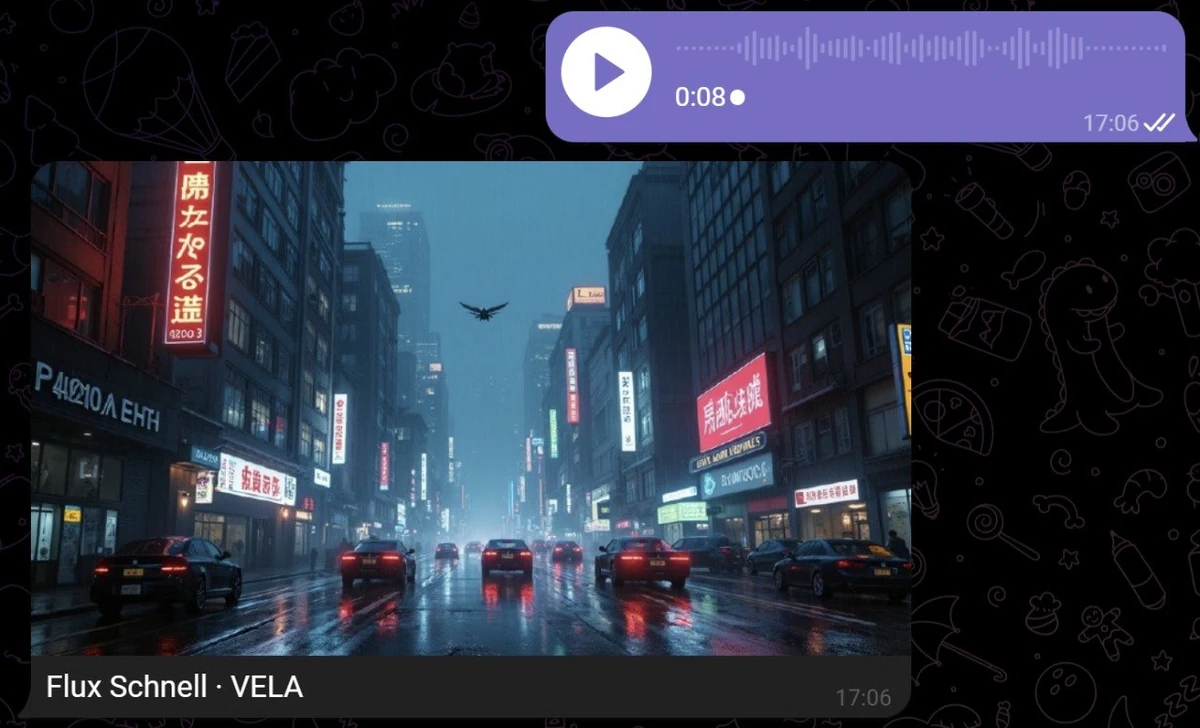
What the module can't do
Worth knowing before you try:
No editing of existing images. Only creation from a description, from scratch. You can't upload a photo and ask "remove the background" or "add a sunset," etc. — that's a different task, not available here.
No inpainting or outpainting. You can't paint over part of an image or extend it beyond its edges.
No style transfer from a reference. You can't upload an example and say "draw in the same style."
Weak with text. Letters, captions, logos in an image — diffusion models are traditionally bad at reproducing text accurately. For typography tasks, it's better to use specialized tools.
A limit of 10 generations a day. When you hit the limit, the AI assistant tells you — new generations become available the next day.
No video generation. Static images only.
Some images get a pseudo-signature. Flux Dev sometimes adds an element that looks like a handwritten artist's signature — more often on illustrative, detailed scenes, less often on landscapes and nature. That's the model's behavior, not an error of the AI assistant.
If you need to analyze photos or extract text from images — that's a separate module, available for free on the Basic plan.
One chat instead of separate apps
For image generation, people usually open Midjourney or ChatGPT with DALL-E — each with its own site, app, and sign-up. With VELA's AI assistant, it's one request in Telegram with no extra subscriptions, settings, or accounts. Right alongside are reminders, flight search, the morning digest, Google Workspace, and other useful modules. Your phone and computer are always at hand, Telegram is installed and open — nothing new to add.
FAQ
Which plan is image generation on? Pro only ($9/mo, paid by card or Telegram Stars). On free Basic, the module isn't available — when you ask, the AI assistant suggests upgrading to a paid plan.
What's the daily generation limit? Up to 10 images a day. The limit resets daily. When you reach it, the AI assistant tells you and suggests continuing the next day.
Can I generate images by voice? Yes. Dictate the description as a voice message — the AI assistant recognizes the audio and creates an image from your description.
Which image formats are supported? Three options: square (1:1), horizontal (landscape), and vertical (portrait). Specify the format in the request, or the AI assistant creates a square image by default.
What if I'm not happy with the result? Describe exactly what to change — the AI assistant creates a new version. Each attempt counts as a separate generation and uses up the daily limit.